Benchmark Overview¶
CUDA Benchmarks¶
Hardware: 10 nodes, each with 4x NVIDIA Volta V100 GPUs (32 GB HBM2), connected via 56G InfiniBand.
Software: NVHPC 24.7, CUDA 11.8.
Libraries:
dtFFTv3.0.0,cuDECOMPv0.6.0,HeFFTev2.4.1, and2DECOMP&FFTlatest from GitHub.Problem Size: A 3D grid of \(1024 \times 1024 \times 1024\) was used for all tests.
Methodology: Each benchmark was run for 50 iterations performing both forward and backward transforms. The reported time is the maximum time taken by any GPU over all iterations.
Precision: Double precision complex-to-complex (C2C) transforms were performed.
Communication Backend: Only MPI-based communication was evaluated for multi-GPU tests.
FFT Libraries: All libraries utilized NVIDIA’s cuFFT for local FFT computations.
Additional information: UCX and CUDA IPC are disabled.
Strong Scaling¶
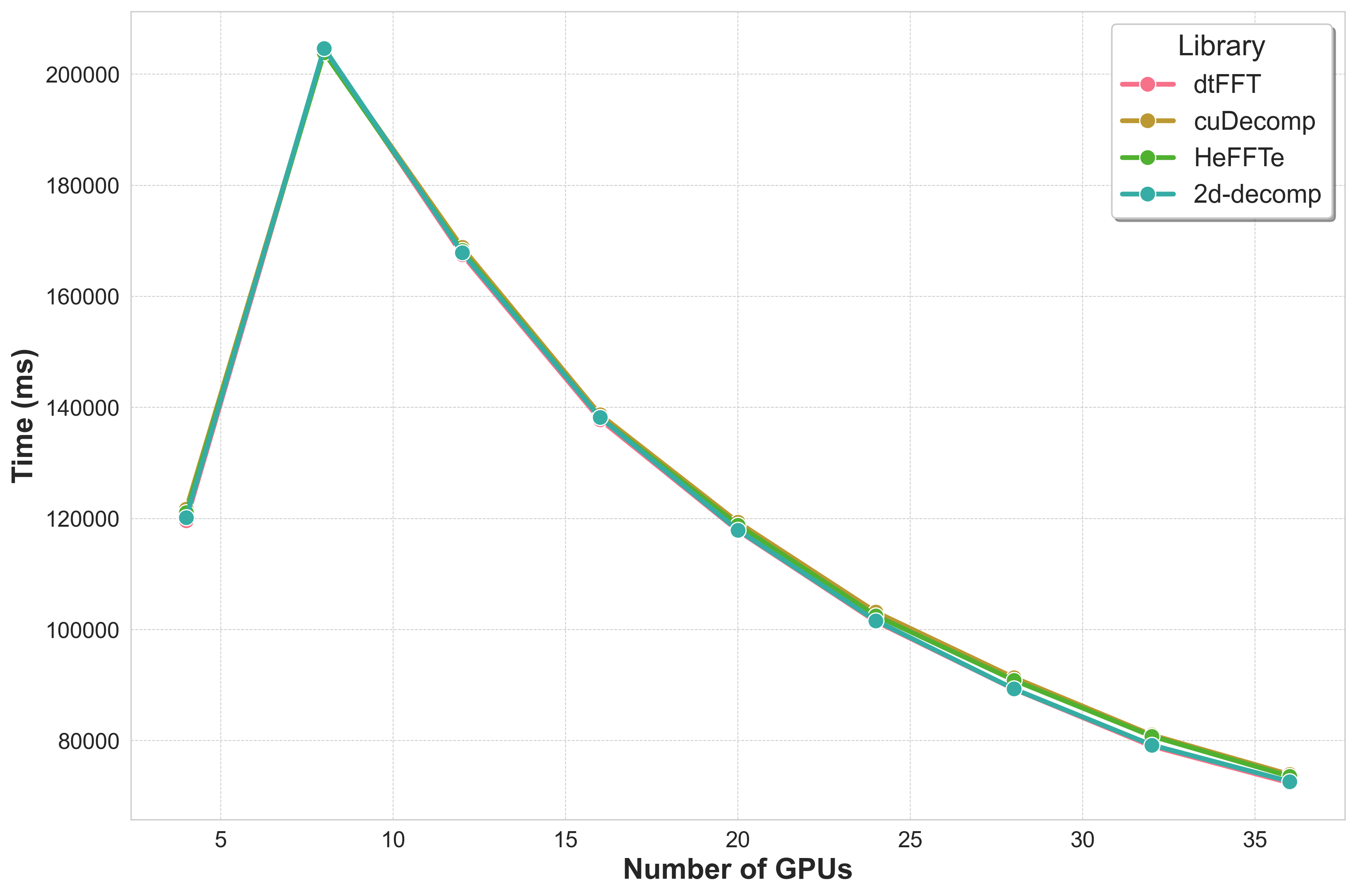
Number of GPUs |
dtFFT |
cuDECOMP |
HeFFTe |
2DECOMP&FFT |
|---|---|---|---|---|
4 |
119626.641 |
121721.242 |
121098.586 |
120167.854 |
8 |
204371.359 |
204187.656 |
203894.516 |
204669.592 |
12 |
167539.578 |
168842.437 |
168267.093 |
167885.206 |
16 |
137827.844 |
138721.703 |
138234.469 |
138201.588 |
20 |
117795.039 |
119350.664 |
118823.680 |
117924.865 |
24 |
101455.992 |
103170.719 |
102516.188 |
101612.259 |
28 |
89294.328 |
91382.023 |
90897.547 |
89335.099 |
32 |
79008.461 |
81047.414 |
80815.453 |
79230.639 |
36 |
72392.461 |
73923.062 |
73583.375 |
72661.824 |
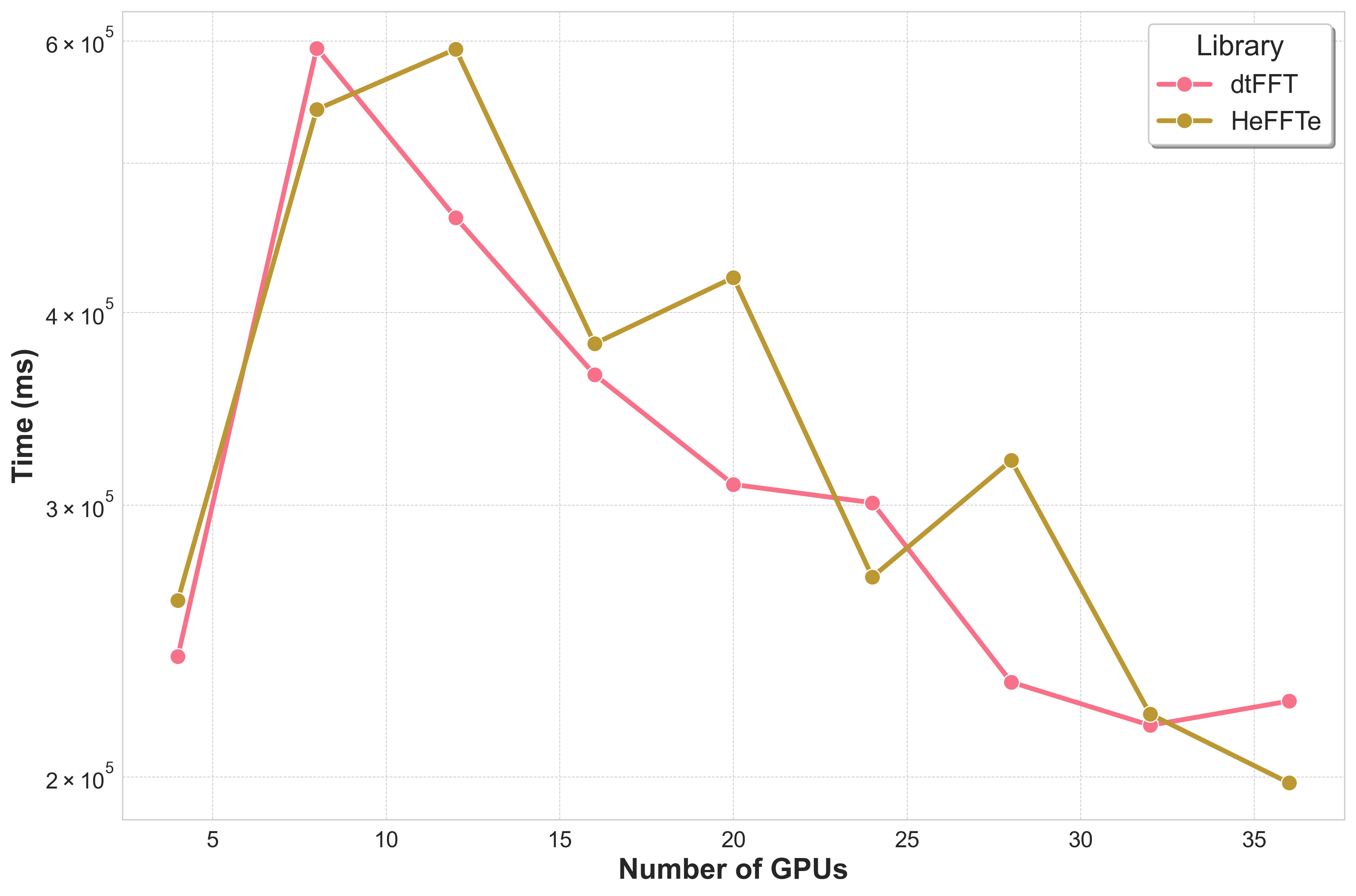
Bricks Strong Scaling¶
Grid decomposition created via MPI_Dims_create.
Host Benchmarks¶
Weak Scaling¶
C2C Double Precision; initial grid is \(128 \times 128 \times 128\); no FFT is executed
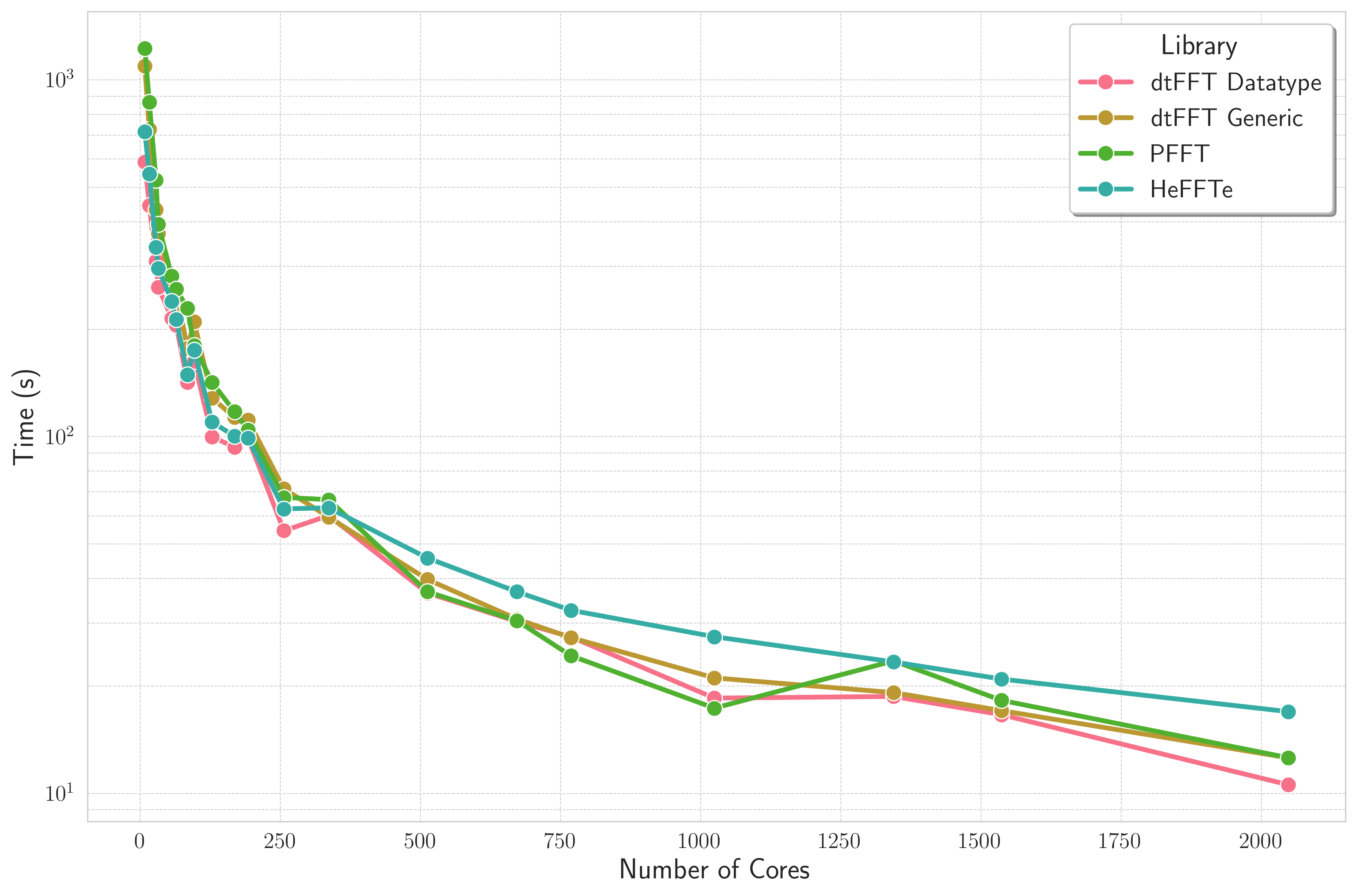
Strong Scaling¶
C2C Double Precision; \(64 \times 2048 \times 2048\); FFTW3 executor
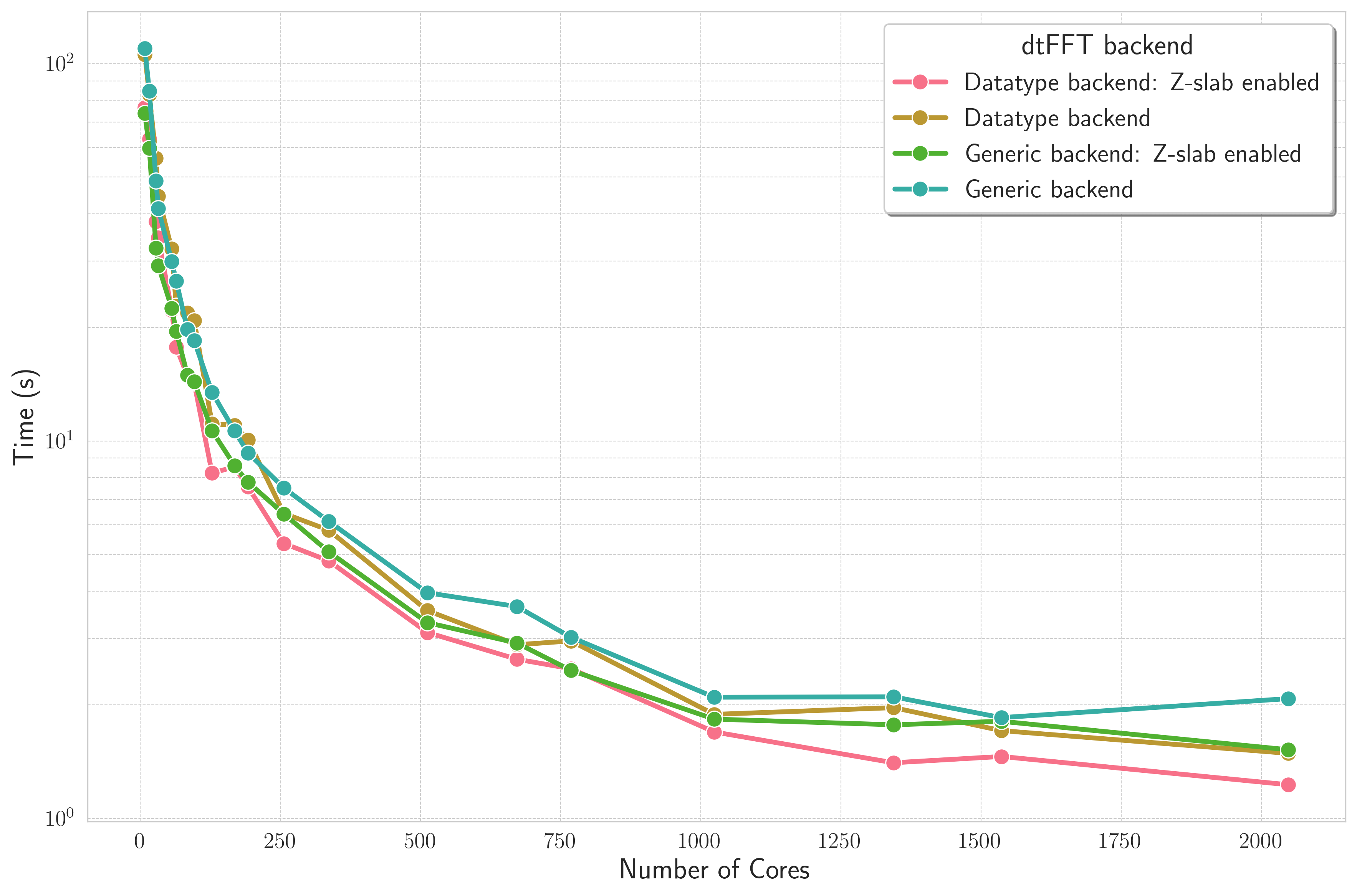
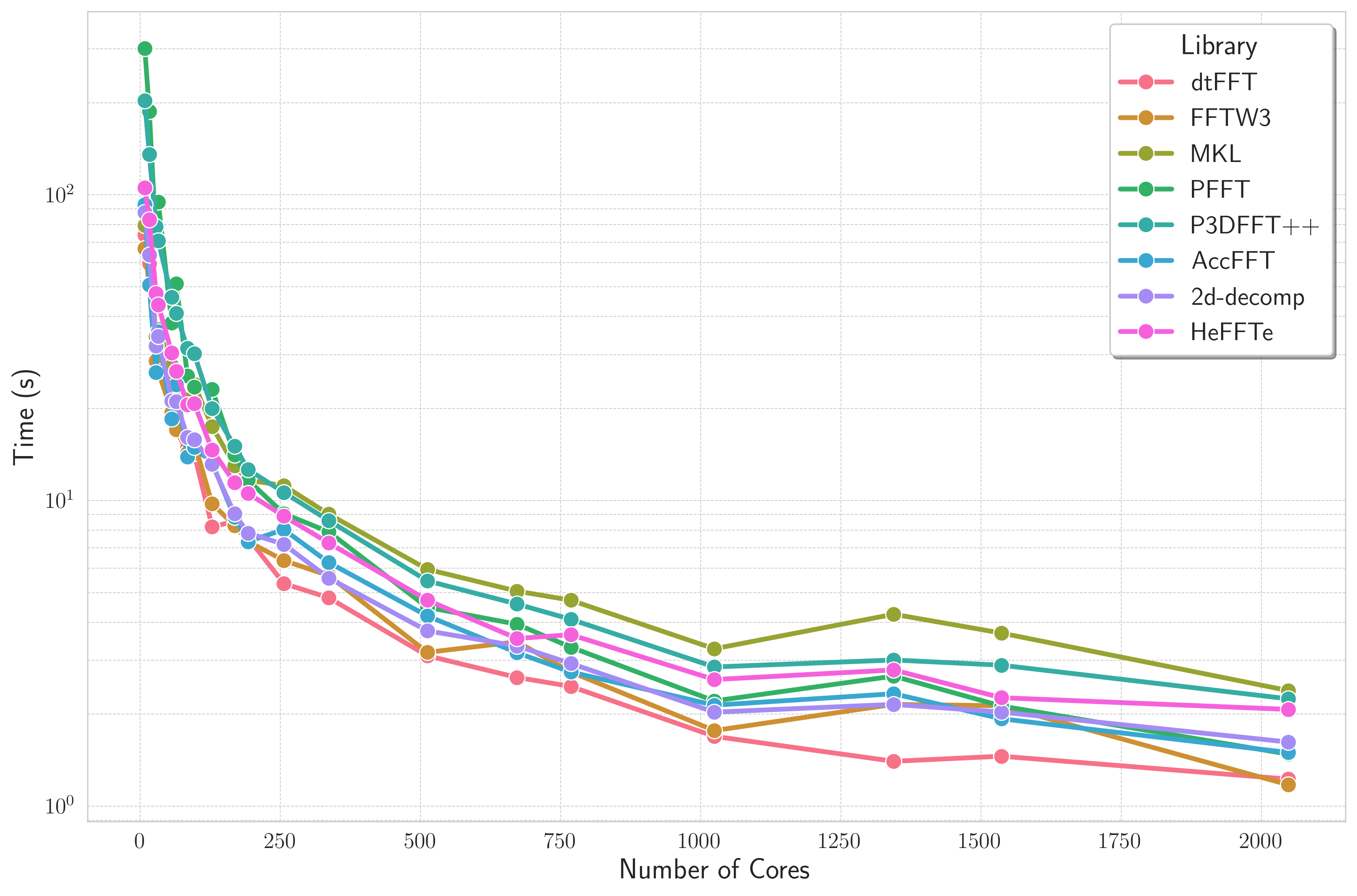
C2C Double Precision; \(2048 \times 2048 \times 64\); FFTW3 executor
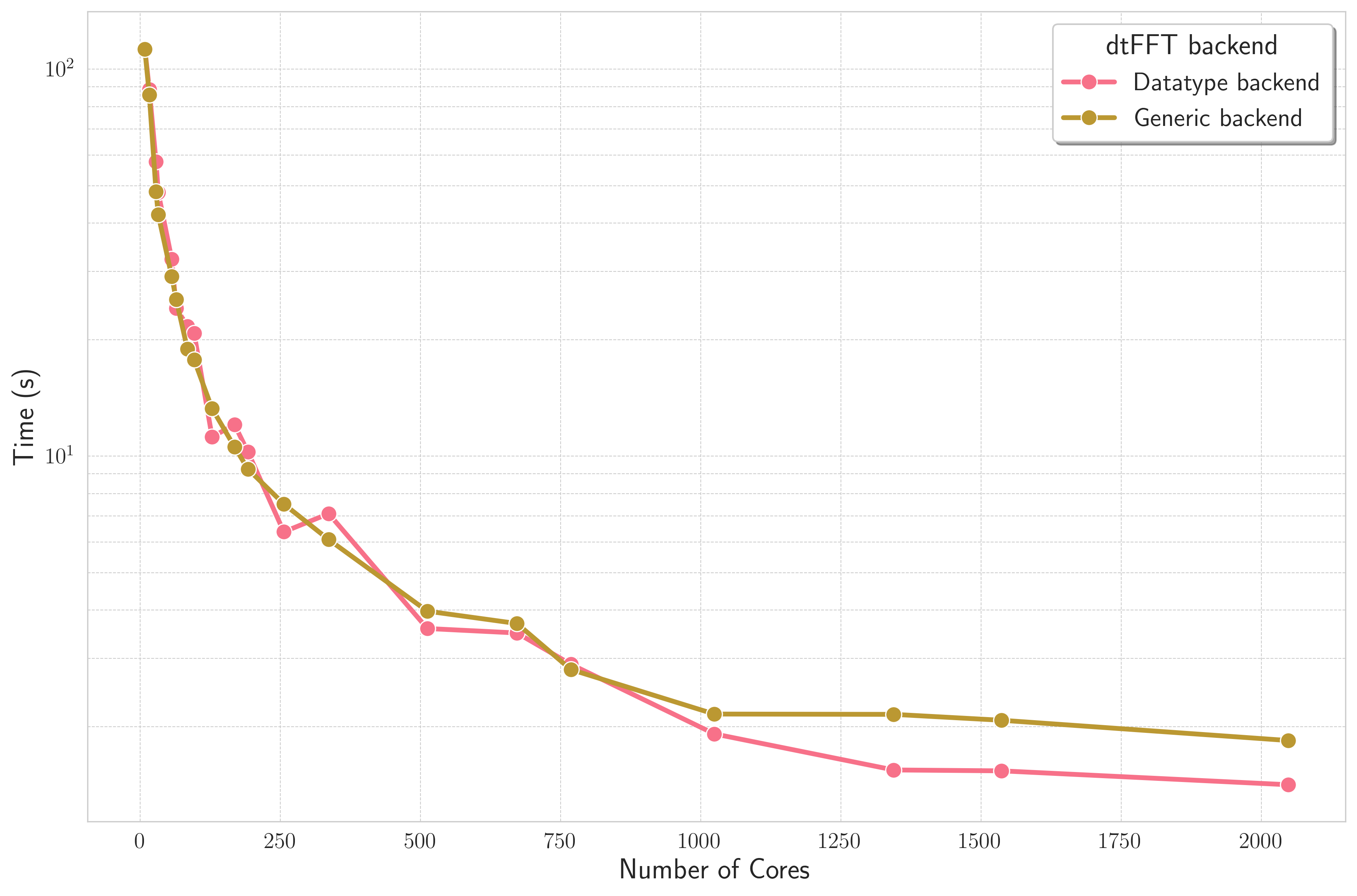
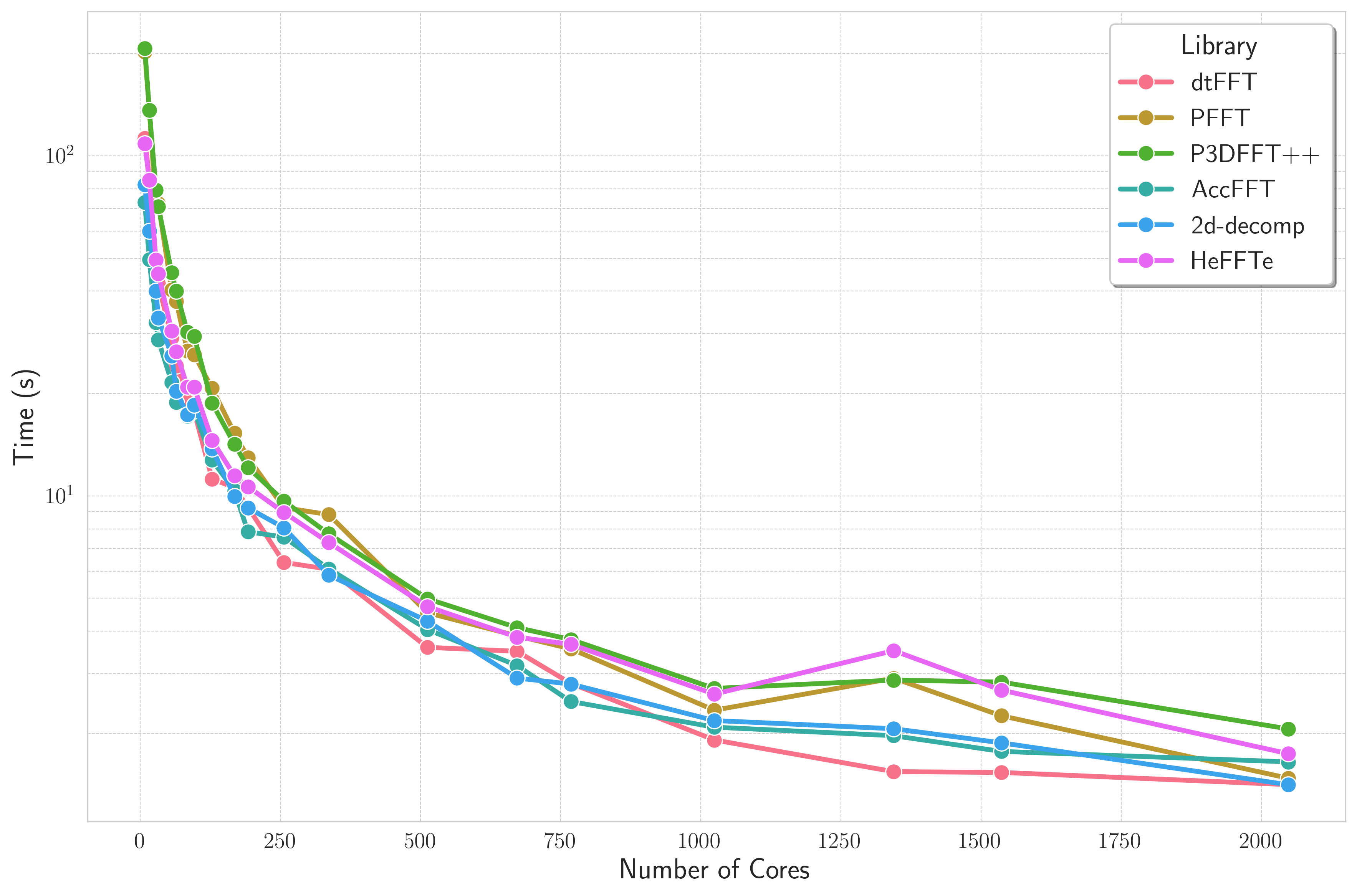
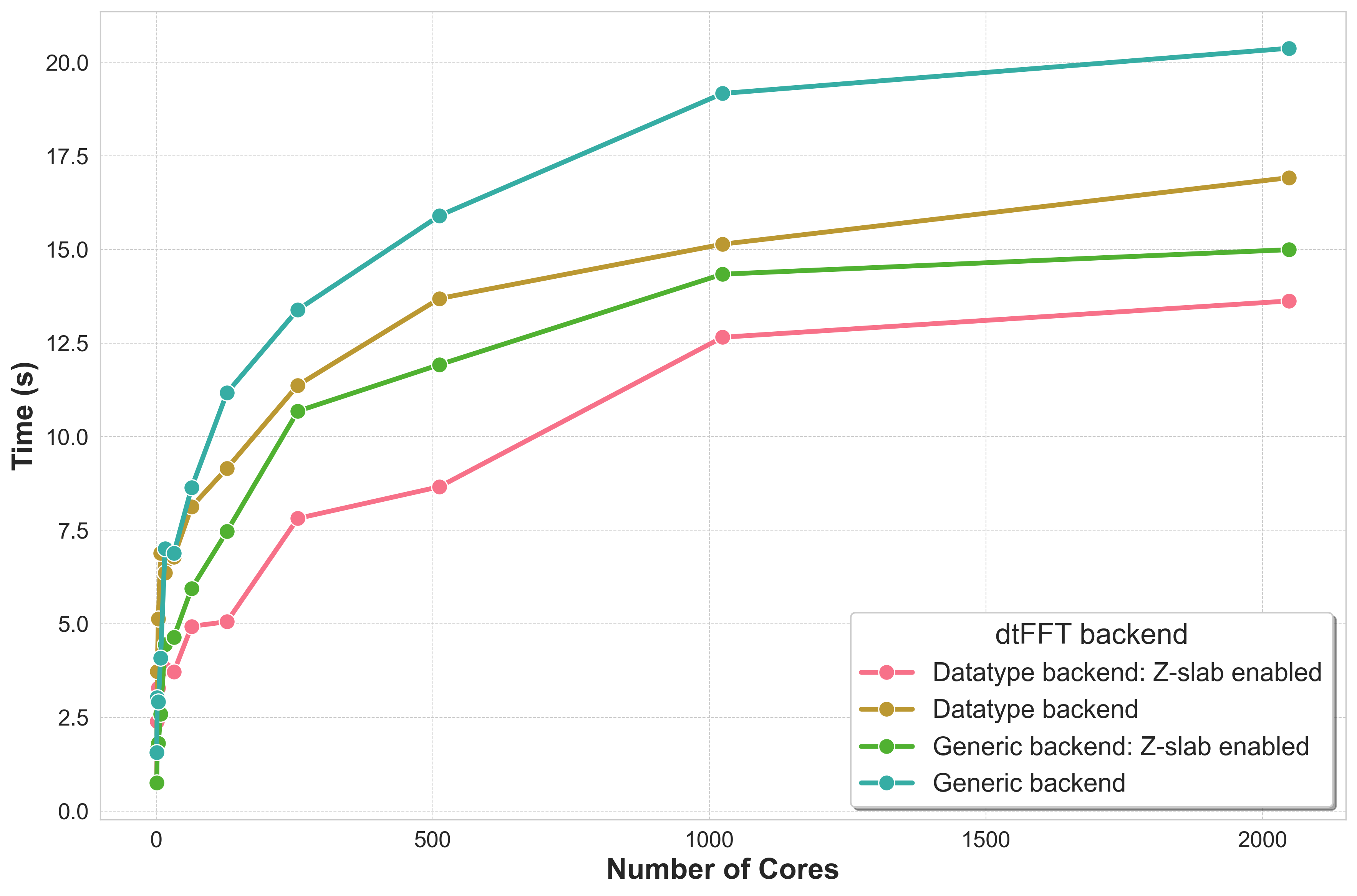
Bricks Strong Scaling¶
C2C Double Precision; \(1024 \times 1024 \times 1024\); FFTW3 executor.
Grid created via MPI_Dims_create.